Главное меню
Вы здесь
9.1 Описательная статистика
9.1 Описательная статистика
Для ознакомления с характеристиками описательной статистики рассмотрим переменную а, отражающую возраст.
-
Загрузите файл hyper, sav и выберите команды меню Analyze (Анализ) Descriptive Statistics (Дескриптивные статистики) Descriptives... (Описательная статистика) Откроется диалоговое окно Descriptives.
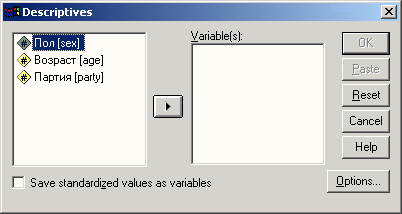
Рис. 9.1: Диалоговое окно Descriptives
-
Перенесите переменную а в список тестируемых переменных, и щелкните на кнопке Options... (Параметры).
Здесь можно задать вычисление следующих статистических характеристик:
-
Среднего значения,
-
Суммы,
-
Стандартного отклонения,
-
Стандартной ошибки,
-
Дисперсии,
-
Минимума,
-
Максимума,
-
Размаха,
-
Эксцесса (вариации),
-
Асимметрии.
-
Установите флажки для вывода следующих характеристик: Mean (Среднее значение), Minimum (Минимум), Maximum (Максимум) и S.E. mean (Стандартная ошибка).
Если анализируется несколько переменных, можно также задать последовательность вывода:
-
в порядке возрастания средних значений,
-
в порядке убывания средних значений,
-
по алфавиту (по именам переменных),
-
согласно списку выбранных целевых переменных.
По умолчанию выбран последний вариант. Если имеется только одна переменная, как в данном примере, порядок не имеет значения.
-
Пометив желаемые характеристики, щелкните на кнопке Continue... (Далее). В главном диалоговом окне укажите, чтобы стандартизованные значения были сохранены в новой переменной открытого файла данных, для чего установите флажок Save standardized values as variables.
-
Запустите вычисление, щелкнув на кнопке ОК. Результат будет показан в окне просмотра:
Descriptive Statistics (Описательная статистика)
N | Minimum | Maximum | Mean | ||
Statistic | Statistic | Statistic | Statistic | Std. Error | Statistic |
Возраст | 174 | 36 | 87 | 62,11 | ,88 |
Valid N (listvise) (Допустимых значений (по списку)) | 174 | ||||
О значении отдельных характеристик описательной статистики можно прочесть в главе 6.
Видно, что в файле данных появилась новая переменная za. Она содержит нормированные значения переменной а (Возраст). По умолчанию к имени исходной переменной спереди дописывается буква z. При этом стандартизация (z-преобразование) значения х выполняется по формуле
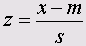
Здесь m — среднее значение переменной, a s — стандартное отклонение.
Проведение стандартизации переменных может быть целесообразным при использовании некоторых статистических методов. Его также можно выполнять в тех случаях, когда несколько переменных, которые имеют различный размах или отличаются на порядки по значению, должны быть приведены к общему показателю. В подобной ситуации сначала необходимо провести стандартизацию этих переменных, а затем, путем усреднения, вывести общее значение из полученных стандартизованых значений (z-зна-чений).