Глава 12. Анализ множественных ответов
Глава 12. Анализ множественных ответов
1. Анализ множественных ответов
Анализ множественных ответов
В этой главе мы рассмотрим особенности кодирования и анализа множественных ответов. Вопросы, на которые можно дать несколько ответов одновременно ( это и есть множественные ответы), имеются во многих анкетных исследованиях. Для кодировкии анализа таких множественных ответов SPSS представляет два различных метода: метод множественной дихотомии и категориальный метод. Оба этих метода рассматриваются в последующих разделах на одном и том же примере. Пример взят из анкетирования членов городской организации политической партии, в котором исследовались их мнения и пожелания.
12.1 Дихотомный метод
12.1 Дихотомный метод
В упомянутой анкете был задан вопрос: "Как можно сделать партию более привлекательной?" Предлагались следующие варианты ответов:
-
больше активности в период между выборами
-
повышение эффективности общих собраний
-
больше неформальных встреч
-
открытые общие собрания
-
большая близость к населению на местах
-
лучше информировать членов партии об актуальных событиях
-
привлечение не членов партии к различным партийным проектам
-
больше мероприятий по актуальным политическим темам на местах
В методе множественной дихотомии для каждой из возможностей ответа определяется отдельная переменная. В рассматриваемом примере для этого понадобится восемь переменных. Если член партии отметит ответ "больше активности в период между выборами ",соответствующая переменная получит значение "1", если нет-"0", если член партии отметит ответ "повышение эффективности общих собраний", соответствующая переменная получит значение "1", если нет-"0",и т.д. для остальных переменных. Таким образом мы получили восемь переменных с кодовыми значениями 0 и 1. Кодовые значения при этом выбираются произвольно, однако для всех ответов они должны быть одинаковы и введены в компьютер на правильном месте.
Ответы на этот и другие вопросы анкетирования членов партии содержаться в файле meinug.sav. Сначала мы посмотрим частотную таблицу ответов на вопрос "Как можно сделать партию более привлекательной?", а затем перекрестную таблицу этого вопроса и пола.
12.1.1 Определение наборов
12.1.1 Определение наборов
Ответы на наш вопрос закодированы вышеописанным способом в переменных att1+attS. В первую очередь мы должны сообщить компьютеру, что эти восемь переменных принадлежат к одному "набору переменных".
-
Загрузите файл meinung.sav.
-
Выберите в меню команды Analyze (Анализ) Multiple Response (Множественные ответы) Define Sets... (Определить наборы)
Откроется диалоговое окно Define Multiple Response Sets (Определение наборов ответов).
-
Выделите в списке исходных переменных переменные att1+att8 и перенесите их в список Variables in Set (Переменные в наборе).
-
Задайте дихотомическую кодировку переменных (опция Dichotomies в группе Variables Are Coded As). Эта настройка выбирается по умолчанию. В поле Counted Value (Учитываемое значение) введите "1".
-
Присвойте набору имя "attrak" и метку "Повышение привлекательности".
-
Щелкните на кнопке Add (Добавить), и созданный набор будет внесен в список наборов множественных ответов (Mult Response Sets).
SPSS начинает имена наборов переменных со знака доллара; следовательно, вновь созданный набор получит имя Sattrak.
-
Щелкните на кнопке Close (Закрыть), чтобы закончить процесс определения набора.
12.1.2 Частотные таблицы для дихотомических наборов
12.1.2 Частотные таблицы для дихотомических наборов
-
Чтобы создать частотную таблицу для дихотомического набора, выберите команды меню Analyze (Анализ) Multiple Response (Множественные ответы) Frequencies... (Частоты)
Рис. 12.1: Диалоговое окно Define Multiple Response Sets
Рис. 12.2: Диалоговое окно Multiple Response Frequencies
Откроется диалоговое окно Multiple Response Frequencies (Частоты множественных ответов).
В списке Mult Response Sets этого диалога отображаются уже определенные наборы переменных; в нашем примере это набор Sattrak.
-
Перенесите набор Sattrak в список Table(s) for (Таблицы для).
-
Щелкните на кнопке ОК.
В окне просмотра появятся следующие результаты:
Group $ATTRAK Повышение привлекательности (Value tabulated = 1) | Pet of Pet of | |||||
dichotomy label | Name Count Responses | Cases | ||||
больше активности в период между выборами | ATT1 | 81 | 20 | ,4 | 77 | ,1 |
повышение эффективности общих собраний | ATT2 | 24 | 6 | ,0 | 22 | ,9 |
больше неформальных встреч | ATT3 | 24 | 6 | ,0 | 22 | ,9 |
открытые общие собрания | ATT4 | 25 | 6 | ,3 | 23 | ,8 |
большая близость к населению на местах | ATT5 | 80 | 20 | ,1 | 76 | ,2 |
лучше информировать членов партии | ATT6 | 51 | 12 | ,8 | 48 | , 6 |
привлечение не членов партии | ATT7 | 46 | 11 | ,6 | 43 | ,8 |
больше мероприятий по актуальным темам | ATT8 | 67 | 16 | ,8 | 63 | ,8 |
Total responses | 398 | 100 | ,0 | 379 | ,0 | |
5 missing cases; 105 valid cases | ||||||
В столбце "Dichotomy label" (Метка дихотомии) приводятся метки переменных, принадлежащих к набору. Показано, что имеется 5 пропущенных и 105 допустимых наблюдений. Отсутствующим наблюдением считается, если ни одна из переменных набора не имеет учитываемого значения (в данном примере значения "1").
Можно получить еще один вариант таблицы, если в диалоговом окне Multiple Response Frequencies установить флажок Exclude cases listwise with dichotomies (Для дихотомических переменных исключать наблюдения по списку). Тогда к пропущенным будут причисляться и те наблюдения, в которых хотя бы одна переменная набора имеет отсутствующее значение — в данном примере не закодирована ни единицей, ни нулем. Это вариант представления может быть полезен, если данный ответ в анкете не определен однозначно.
Для наблюдаемых частот выводятся два разных процентных значения. При определении первого из них наблюдаемая частота отнесена к общему числу ответов "да" (398), а при определении второго — к общему числу допустимых наблюдений (105). Однако самая удобная процентная характеристика, а именно процент от количества всех наблюдений (110), отсутствует. Первую строку частотной таблицы можно интерпретировать, например, так: 81 член партии считает, что большая активность в период между выборами может повысить привлекательность партии. Это 20,4 % от общего количества положительных ответов или 77,1 % членов партии, которые дали хотя бы один вариант ответа.
Как мы уже говорили, в этой таблице, к сожалению, отсутствует процент от общего количества опрошенных членов партии (НО наблюдений). Если вам нужна эта наиболее информативная характеристика, ее можно вычислить вручную или применить следующий прием.
-
С помощью команд синтаксиса
COMPUTE att9 = 1.
EXECUTE.
создайте новую переменную и поместите ее в набор. Вы получите следующую частотную таблицу:
Group $ATTRAK Повышение привлекательности (Value tabulated = 1) | Pct of | Pct of | ||||
Dichotomy label | Name | Count Responses | Cases | |||
больше активности в период между выборам | ATT1 | 81 | 15 | , 9 | 73 | ,6 |
повышение эффективности общих собраний | ATT2 | 24 | 4 | ,7 | 21 | / & |
больше неформальных встреч | ATT3 | 24 | 4 | , 7 | 21 | ,8 |
открытые общие собрания | ATT4 | 25 | 4 | , 9 | 22 | , 7 |
большая близость к населению на местах | ATT5 | 80 | 15 | ,7 | 72 | , 7 |
лучше информировать членов партии | ATT6 | 51 | 10 | ,0 | 46 | ,4 |
привлечение не членов партии | ATT7 | 46 | 9 | ,1 | 41 | ,8 |
больше мероприятий по актуальным темам | ATT8 | 67 | 13 | ,2 | 60 | ,9 |
ATT9 | 110 | 21 | ,7 | 100 | ,0 | |
Total responses | 508 | 100 | ,0 | 461 | ,8 | |
0 missing cases; 110 valid cases | ||||||
Теперь расчет процентов от общего количества ответов потерял смысл, а второй столбец процентов относится к фактическому числу всех наблюдений. То есть 73,6 % всех опрошенных членов партии считают, что большая активность в период между выборами может повысить привлекательность партии.
1.gif

2.gif

12.1.3 Таблицы сопряженности с дихотомическими наборами
12.1.3 Таблицы сопряженности с дихотомическими наборами
Таблицы сопряженности можно создавать между двумя наборами переменных, а также между набором и "обычной" переменной. Так, к примеру, нам необходимо в одной таблице сопряженности отобразить соотношение между набором Sattrak и переменной geschl, которая с помощью кодировок 1 = женский и 2 = мужской характеризует пол респондентов.
-
Выберите в меню команды Analyze (Анализ) Multiple Response (Множественные ответы) Crosstabs... (Таблицы сопряженности) Появится диалоговое окно Multiple Response Crosstabs.
Рис. 12.3: Диалоговое окно Multiple Response Crosstabs
В списке исходных переменных показаны переменные файла meinung.sav. В списке наборов множественных ответов показан ранее определенный набор.
-
Перенесите в список переменных строк набор Sattrak, а в список переменных столбцов — переменную geschl. Эта переменная появится в списке столбцов с двумя вопросительными знаками, заключенными в скобки. Если таблица сопряженности строится между элементарными переменными (не являющимися наборами) и наборами, то для первых следует задать диапазон значений.
-
Щелкните на кнопке Define Ranges... (Определить диапазоны).
Откроется диалоговое окно Multiple Response Crosstabs: Define Variable Range (Таблицы сопряженности для множественных ответов: Определить диапазон переменной).
-
Задайте минимальное значение (Minimum) "1", а максимальное (Maximum) — "2".
-
Подтвердите выбор кнопкой Continue. Теперь вопросительные знаки заменены значениями "1" и "2".
-
Щелкните на кнопке Options... (Параметры).
Откроется диалоговое окно Multiple Response Crosstabs: Options.

Рис. 12.4: Диалоговое окно Multiple Response Crosstabs: Define Variable Range
Абсолютные частоты в ячейках выводятся всегда. Дополнительно в группе Cell Percentages (Проценты в ячейках) можно выбрать одну или несколько характеристик:
-
Row (По строкам): Отображаются проценты для строки.
-
Column (По столбцам). Отображаются проценты для столбца.
-
Total (Полные): Отображаются общие проценты для таблицы.
В группе Percentages based on (Проценты вычисляются на основе) можно выбрать одну из следующих опций:
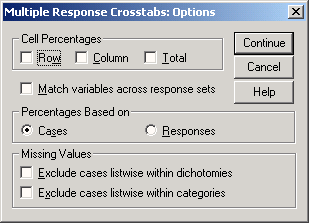
Рис. 12.5: Диалоговое окно Multiple Response Crosstabs: Options
-
Cases (Наблюдения): Это настройка по умолчанию. Основанием для расчёта процентных показателей в ячейках является число наблюдений, соответствующие количеству опрошенных респондентов.
-
Responses (ответы): Основой расчета процентного отношения в ячейке является количество ответов. Для наборов множественных дихотомий количество ответов равно частоте учитываемого значения во всех наблюдениях.
Обработка пропущенных значений уже рассматривалась в разделе 12.1.2.
Флажок Match variables across response sets (Учитывать переменные из наборов попарно) имеет смысл, только если таблица сопряженности строится на основе двух наборов переменных. В этом случае первая переменная из первого набора сочетается с первой переменной из второго набора, и т.д.
-
В группе Percentages based on сохраните настройку по умолчанию Cases.
-
В группе Cell Percentages установите флажок Column.
-
Подтвердите ввод кнопкой Continue, а затем — ОК. В окне просмотра будет показана следующая таблица.
* * * СR0SSТABULATION * * * | |||||
$ATTRAK (tabulating 1) | Erhohung | der Attraktivitat | |||
by GESCHL Geschlecht | |||||
GESCHL | |||||
Count Iweiblich | maennlic | ||||
Col pet Ih | Row | Total | |||
I |
| ||||
I | 1 | I | 2 | I | |
$ATTRAK X | |||||
ATT1 I | 21 | + -I | 60 | + I | 81 |
mehr Prasenz zwische I | 72,4 | I | 78,9 | I | 77,1 |
+ — | _ _ _ | + — | _ _ _ | + | |
ATT2 I | 6 | I | 18 | I | 24 |
Verbesserung der Hit I | 20,7 | I | 23,7 | I | 22,9 |
+ — | _ _ _ | + — | _ _ _ | + | |
ATT3 I | 5 | I | 19 | I | 24 |
mehr gesellige Zusam I + - | 17 ,2 | I | 25, 0 | I | 22, 9 |
ATT4 I | 2 | + - I | 23 | + I | 25 |
offentlich zuganglic I | 6,9 | I | 30,3 | I | 23,8 |
+ - | _ _ _ | + - | _ _ _ | + | |
ATT5 I | 23 | I | 57 | I | 80 |
mehr Burgernahe mit I | 79,3 | I | 75,0 | I | 76,2 |
+ - | _ _ _ | + — | _ _ _ | + | |
ATT6 I | 14 | I | 37 | I | 51 |
bessere Information I | 48,3 | I | 48,7 | I | 48,6 |
+ - | _ _ _ | + - | _ _ _ | + | |
ATT7 I | 12 | I | 34 | I | 46 |
Beteiligung von Nich I | 41,4 | I | 44,7 | I | 43,8 |
+ - | _ _ _ | + — | _ _ _ | + | |
ATT 8 I | 18 | I | 49 | I | 67 |
mehr Veranstaltungen I | 62,1 | I | 64,5 | I | 63,8 |
| _ _ _ | + — | _ _ _ | + | |
Column | 29 | 76 | 105 | ||
Total | 27, 6 | 72,4 | 100,0 | ||
Percents and totals based on respondents 105 valid cases; 5 missing cases
Полученные проценты соответствуют отношению частот к числу допустимых наблюдений; ср. заключения сделанные в разделе 12.1.2. К сожалению, длина меток переменных ограничивается лишь двадцатью символами.
Если сравнить оба пола, то значительное различие заметно только при анализе переменной att4: 30,3 % мужчин считают, что открытые собрания повышают привлекательность партии, но лишь 6,9 % женщин придерживаются этого мнения.
К сожалению, для множественных ответов SPSS не проводит проверку значимости с помощью критерия хи-квадрат. Если выполнение такой проверки необходимо, то следует поступить, как указано в разделе 8.7.2.
3.gif

4.gif

5.gif

12.2 Категориальный метод
12.2 Категориальный метод
Альтернативный способ кодирования множественных ответов предоставляет метод множественных категорий, или категориальный. Для применения этого метода должно быть известно максимальное количество возможных ответов. Это количество можно, например, задать в анкете (указанием типа "Отмечайте не более пяти вариантов") или установить после проверки анкет.
Чтобы узнать, почему члены партии, не имеющие партийного поручения, не хотят его получить или не участвуют в партийной работе иным образом, в анкете задавался вопрос "Что мешает Вашему участию в партийной работе?". После вопроса было помещено указание, что можно отметить не более пяти из приводимых вариантов ответа:
Мне неизвестны возможности для участия в работе | 1 |
Функции уже распределены | 2 |
Поведение функционеров | 3 |
Групповщина не дает стимула для участия | 4 |
У меня слишком мало политического опыта | 5 |
Я опасаюсь негативного влияния на свою работу/карьеру | 6 |
Я опасаюсь негативного влияния на свою личную жизнь | 7 |
Не желаю | 8 |
Здоровье не позволяет | 9 |
Так как количество ответов составляет не более пяти, для того, чтобы закодировать все варианты ответов будет достаточно пяти переменных. В файле meinung.sav это переменные mit1+mitS, которые после загрузки файла отображаются в редакторе данных.
Каждая из пяти переменных кодируется одинаковыми категориями, причем вне зависимости от количества данных ответов область этих пяти переменных заполняется слева направо.
Так, в первом наблюдении при ответе на вопрос отмечены категории 3, 4 и 6 (Поведение функционеров, Групповщина, Негативное влияние в работе). Следующие три респондента не отметили ни одного ответа, в наблюдении 8 дан только один ответ (Категория 1, "Неизвестны возможности участия") и т.д. Для этого вопроса мы также построим частотную таблицу и таблицу сопряженности с полом. Но сначала определим набор переменных.
Рис. 12.6: Множественные отпеты при категориальном методе
6.gif

12.2.1 Определение наборов
12.2.1 Определение наборов
Сначала следует определить набор. Выполите следующие действия:
-
Выберите в меню команды Analyze (Анализ) Multiple Response (Множественные ответы) Define Sets... (Определить наборы)
Появится уже известное вам диалоговое окно Define Multiple Response Sets. В списке исходных переменных Set Definition (Определение набора) показаны переменные файла meimmg.sav.
-
Выделите переменные mit1+mitS и перенесите их в список Variables in Set (Переменные в наборе).
-
Задайте категориальную кодировку переменных (опция Categories). В полях Range — through укажите диапазон "1" + "9".
-
Присвойте набору имя "mitwirk" и метку "Препятствия в сотрудничестве".
-
Щелкните на кнопке Add (Добавить), и созванный набор будет внесен в список наборов множественных ответов (Mult Response Sets).
-
Щелкните на кнопке Close, чтобы завершить определение набора.
12.2.2 Частотные таблицы для категориальных наборов
12.2.2 Частотные таблицы для категориальных наборов
-
Для того, чтобы создать частотную таблицу, выберите в меню команды Analyze (Анализ) Multiple Response (Множественные ответы) Frequencies... (Частоты) Откроется диалоговое окно Multiple Response Frequencies.
-
Перенесите набор Smitwirk в список Table(s) for.
-
Щелкните на кнопке ОК.
В окне просмотра будет показана следующая частотная таблица.
Group $MITWIRK Препятствия в сотрудничестве Pet of Pet of | ||||||
Category label Code | CountResponses | Cases | ||||
Неизвестны возможности участия | 1 | 24 | 12 | ,8 | 27 | ,6 |
Функции уже распределены | 2 | 26 | 13 | ,9 | 29 | , 9 |
Поведение функционеров | 3 | 36 | 19 | ,3 | 41 | ,4 |
Групповщина | 4 | 20 | 10 | ,7 | 23 | ,0 |
Недостаток политического опыта | 5 | 29 | 15 | ,5 | 33 | , 3 |
Негативное влияние, в работе | 6 | 8 | 4 | ,3 | 9 | ,2 |
Негативное влияние в личной жизни | 7 | 6 | 3 | ,2 | 6 | , 9 |
Нежелание | 8 | 14 | 7 | ,5 | 16 | , 1 |
Здоровье | 9 | 24 | 12 | ,8 | 27 | , 6 |
Total responses | 187 | 100 | ,0 | 214 | ,9 | |
23 missing cases; 87 valid cases | ||||||
В столбце "Category label" (Метки категорий) показаны (единообразные) метки значений переменных, объединенных в набор. Показано, что имеется 23 пропущенных и 87 допустимых наблюдений. Наблюдение считается пропущенным, если ни одна из переменных, принадлежащих к набору не имеет кодового значения
Можно получить еще один вариант таблицы, если в диалоговом окне Multiple Response Frequencies установить флажок Exclude cases listwise with categories (Для категориальных переменных исключать наблюдения по списку). Тогда допустимыми будут считаться только наблюдения, в которых все переменные набора имеют кодовые значения.
Обе процентные характеристики уже рассматривались в разделе 12.1.2. Первую строку частотной таблицы можно интерпретировать следующим образом: 24 члена партии считают, что их участию в партийной работе мешает то, что им неизвестны возможности такого участия. Это 12,8 % данных ответов и 27,6 % респондентов, которые дали хотя бы один вариант ответа.
12.2.3 Таблицы сопряженности с категориальными наборами
12.2.3 Таблицы сопряженности с категориальными наборами
На основе наборов со множественными категориями также можно строить таблицы сопряженности с другими переменными. Для примера рассмотрим таблицу сопряженности между набором Smitwirk и переменной geschl. Выполните следующие действия:
-
Выберите в меню команды Analyze (Анализ) Multiple Response (Множественные ответы) Crosstabs... (Таблицы сопряженности)
Появится диалоговое окно Multiple Response Crosstabs.
-
Перенесите в список переменных строк набор Smitwirk, а в список переменных столбцов — переменную geschl. Эта переменная появится в списке столбцов с двумя вопросительными знаками, заключенными в скобки.
-
Щелкните на кнопке Define Ranges... (Определить диапазоны).
Откроется диалоговое окно Multiple Response Crosstabs: Define Variable Range.
-
Введите минимальное значение 1 и максимальное "2".
-
Подтвердите выбор кнопкой Continue.
-
Щелкните на кнопке Options... (Параметры).
Откроется диалоговое окно Multiple Response Crosstabs: Options.
-
В группе Percentages based on сохраните настройку по умолчанию Cases.
-
В группе Cell Percentages установите флажок Column.
-
Подтвердите ввод кнопкой Continue, а затем — ОК.
В окне просмотра будет показана следующая таблица сопряженности.
*** CROSSTABULATION * ** | |||||||||
$MITWIRK (group) Scheiterungby GESCHL Geschlecht der Mitwirkung | |||||||||
GESCHL | |||||||||
Count Iweiblich maennlic | |||||||||
Col pet | I | h | ROW | ||||||
I | Total | ||||||||
I | 1 | I | 2 | I + I | 24 | ||||
1 | + - I | 7 | + - - I | 17 | |||||
Moglichkeiten nicht | I | 30,4 | I 26 | ,6 | I | 27,6 | |||
+ - | _ _ _ | + — — | — — | + | |||||
2 | I | 3 | I | 23 | I | 26 | |||
Mandate bereits bese | I | 13,0 | I 35 | ,9 | I | 29,9 | |||
+ - | + — — | + | |||||||
3 | I | 10 | I | 26 | I | 36 | |||
Fuhrungs verbal ten de | I | 43,5 | I 40 | ,6 | I | 41,4 | |||
+ - | _ _ _ | •f - — | — — | + | |||||
4 | I | 4 | I | 16 | I | 20 | |||
keine Forderung wage | I | 17 ,4 | I 25 | ,0 | I | 23,0 | |||
+ - | — — — | + — — | — — | + | |||||
5 | I | 11 | I | 18 | I | 29 | |||
zu wenig politische 6 | I + — I | 47 ,8 | I 28 | ,1 | I + I | 33,3 8 | |||
0 | + - - I | 8 | |||||||
Befurchtung beruflic 7 | I + -I | , 0 | I 12 | ,5 | I + I | 9,2 6 | |||
0 | + - — I | 6 | |||||||
Befurchtung persqnli | I | , 0 | I 9 | ,4 | I | 6,9 | |||
+ — | _ _ _ | + - - | — — | + | |||||
8 | I | 4 | I | 10 | I | 14 | |||
nichts bewegen konne | I | 17,4 | I 15 | ,6 | I | 16,1 | |||
+ - | _ _ _ | + - - - | - - + | ||||||
9 | I | 7 | I | 17 I | 24 | ||||
gesundheitliche | Grun | I | 30,4 | I | 26,6 I | 27,6 | |||
+ — | _ _ _ | + - - | - — - + | ||||||
Column | 23 | 64 | 87 | ||||||
Total | 26,4 | 73,6 | 100,0 | ||||||
Percents | and | totals based | on | respondents | |||||
S7 | valid | cases ; | 23 | missing cases | |||||
Процентные значения рассчитываются на основе количества допустимых наблюдений. Если сравнить оба пола, то значительное различие заметно только в частоте упоминания мнения, что функции уже распределены и в боязни негативного влияния на работу и личную жизнь; такие ответы мужчины дают чаще. Женщины, напротив, чаще ссылаются на недостаток политического опыта.
12.3 Упражнение
12.3 Упражнение
В заключение проведем анализ множественных ответов на следующем примере. При анкетировании 530 туристов в Кении задавался вопрос о влиянии туризма. Рассмотрим интересующий нас отрывок из этой анкеты:

Варианты ответов на вопрос "Какое влияние, по Вашему мнению, оказывает туризм в Кении?" закодированы по методу множественных категорий. При этом установлено, что было зачеркнуто не более шести возможных ответов. Для шести вариантов определены переменные vnl+vn6. Эти переменные могут иметь следующие значения:
1 = "Приток валюты"
2 = "Подорожание"
3 = "Нагрузка на окр. среду"
4 = "Рабочие места"
5 = "Развитие инфраструктуры"
6 = "Переселение в города"
7 = "Взаимопонимание"
8 = "Разрушение культуры"
9 = "Сохранение культуры"
Загрузите файл kenia.sav.
-
Определите набор переменных. Перенесите в набор переменные vnKvn6. Задайте категориальную кодировку (активируйте опцию Categories в группе Variables Coded by...). Установите диапазон от 1 до 9.
-
Присвойте набору имя "tour" и метку "Влияние туризма".
-
Щелкните на кнопке Add, чтобы добавить сформированный набор в список наборов.
-
Проведите частотный анализ набора Stour как было описано выше. Вы получите следующий результат:
Group $TOUR Влияние туризма | ||||
Pet of | Pet of | |||
Category label Code | Count | Responses | Cases | |
Приток валюты | 1 | 457 | 22,7 | 88,2 |
Подорожание | 2 | 105 | 5,2 | 20,3 |
Нагрузка на окр. среду | 3 | 209 | 10,4 | 40,3 |
Рабочие места | 4 | 441 | 21,9 | 85,1 |
Развитие инфраструктуры | 5 | 170 | 8,4 | 32,8 |
Переселение в города | 6 | 125 | 6,2 | 24,1 |
Взаимопонимание | 7 | 206 | 10,2 | 39,8 |
Разрушение культуры | 8 | 262 | 13,0 | 50,6 |
Сохранение культуры | 9 | 41 | 2,0 | 7,9 |
Total responses | 2016 | 100,0 | 389 ,2 | |
12 missing cases; 518 valic | i cases | |||
Постройте перекрестные таблицы набора Stour последовательно с переменными g (пол), s (образование) и alter (возраст). Проинтерпретируйте результаты самостоятельно.
7.gif

12.4 Сравнение дихотомного и категориального методов
12.4 Сравнение дихотомного и категориального методов
Дихотомный метод | Категориальный метод |
Особенности: | Особенности: |
• Определяется по одной переменной для каждого варианта ответа. | • Оценка максимального количества возможных ответов. |
• Отображение множественных ответов с помощью нескольких дихотомических переменных. | в Определение такого же числа переменных, соответствующего максимальному количеству возможных ответов. |
• Переменные объединяются в наборы из нескольких дихотомий. | • В наборы, соответствующие множественным ответам, объединяются переменные из нескольких категорий. |
Преимущества: | Преимущества: |
• Предварительная оценка максимального количества выбранных вариантов ответов не требуется. | • Меньшее число переменных, если количество вариантов ответов, выбранных в каждом отдельном случае, меньше совокупного количества возможных вариантов ответов. |
Недостатки: | Недостатки: |
• Если количество всех возможных ответов велико, а максимальное количество ответов, выбранных в каждом отдельном случае мало, то затрачивается слишком много переменных по сравнению с категориальным методом. | • Вследствие распределения по разным переменным при проведении последующего анализа затруднено получение совокупного результата. |
О недостатке категориального метода, отмеченном в таблице, следует рассказать подробнее. Например, если потребуется подвергнуть переменную с дихотомическим кодированием att3 из файла mcinung.sav ("неформальные встречи повышают привлекательность партии") какому-либо последующему анализу, то это можно будет сделать без особого труда. Это такая же переменная, как и все остальные.
Но если мы рассмотрим ответ "У меня слишком мало политического опыта" на вопрос "Что мешает Вашему участию в партийной работе", то этот вариант ответа нельзя идентифицировать с помощью однозначно определенной переменной. Этому варианту ответа будет соответствовать одна из переменных mitl-mit5, причем привязка к одной их этих переменных будет меняется от наблюдения к наблюдению.
Чтобы решить эту проблему, следует с помощью команды DO REPEAT (см. раздел 26.3) создать новую переменную:
COMPUTE wenigerf=0.
DO REPEAT mit=mitl to mit5.
IF mit=5 wenigerf=1
END REPEAT.
EXECUTE.
Переменная wenigerf своими кодовыми значениями 1 = да и 0 = нет будет указывать, ответил ли член партии, что у него мало политического опыта, или нет. Эту переменную можно использовать при последующем анализе.
Данный недостаток категориального метода мы считаем настолько значительным, что рекомендуем применять дихотомный метод.