Глава 26. Программирование
Глава 26. Программирование
1. Программирование
Программирование
Пользователи, давно работающие с программой SPSS, в особенности, если им приходилось использовать ее на больших ЭВМ, уже привыкли давать описание данных и формулировать желаемый метод их обработки по строгим синтаксическим правилам в виде некоторой программы на языке SPSS.
Выгода такого подхода заключается в том, что пользователю не приходится постоянно пребывать в диалоговом режиме, а можно просто наблюдать, как компьютер выполняет единожды заданные команды. В связи с необходимостью написания команд и контроля командного синтаксиса, пользователь будет вынужден лучше продумывать свои шаги и, быть может, у него появится более чёткое понимание статистических методов используемых в программе.
Наверняка найдётся немало пользователей, охотно решающих свои проблемы в работе с SPSS именно таким методом. Но даже новички в SPSS, которые используют SPSS for Windows именно потому, что здесь есть возможность работы через диалоговые окна и не желают изучать синтаксис программы, также смогут почерпнуть для себя немало полезного, познакомившись с синтаксисом. Так, в области отбора и модификации данных, а также при выполнении некоторых статистических методов, имеются команды и опции, которые доступны только через синтаксис. Или, к примеру, имеется процедура MATRIX (Матрица), предназначенная для проведения операций с матрицами, которая может быть задействована исключительно при помощи соответствующего программного синтаксиса.
Конечно же, в рамках данной книги, которая как раз и направлена на изучение техники работы в Windows без привлечения синтаксиса программы, не получится дать подробное и полное описание синтаксиса SPSS.
Следующие разделы предназначены с одной стороны для тех пользователей, которые уже знакомы с синтаксисом программы, но с другой, возможно, послужат мотивацией к более подробному изучению данной темы для начинающих пользователей SPSS. В первом разделе будут представлены некоторые основные синтаксические правила. Второй раздел посвящён изучению работы с готовыми SPSS-программами для Windows, третий раздел — тому, как отдельные команды при помощи синтаксиса могут быть включены в диалоговый расчётный процесс, и наконец в четвёртом разделе будут рассмотрены два примера использования процедуры MATRIX (Матрица).
В пятом разделе речь пойдёт о том, как при помощи так называемых сценариев можно автоматизировать выполнение некоторых задач.
26.1 Основные синтаксические правила
26.1 Основные синтаксические правила
Элементы программного языка SPSS можно разделить на следующие категории:
-
Команда (инструкция): инструкция, управляющая процессом работы SPSS.
-
Вспомогательная команда: дополнительная инструкция к команде SPSS. В одну команду может входить несколько вспомогательных команд.
-
Спецификации: некоторые данные, дополняющие команду или вспомогательную команду. Спецификации могут содержать ключевые слова, цифры, арифметические операции, имена переменных и специальные разделительные знаки.
-
Ключевые слова: слова, применяемые в спецификациях, которым в SPSS предопределено некоторое значение.
Рассмотрим синтаксис теста Стьюдента для зависимых переменных:
T-TEST
PAIRS= chol0
WITH choll (PAIRED)
/CRITERIA=CIN(.95)
/MISSING=ANALYSIS.
Здесь T-TEST - команда. PAIRS, CRITERIA и MISSING - вспомогательные команды, после знака равенства в этих командах идут соответствующие спецификации. WITH, CIN и ANALYSIS являются ключевыми словами.
При написании и редактировании командного синтаксиса следует учесть следующие простые правила:
-
Каждая команда должна начинаться с новой строки и заканчиваться тачкой (.).
-
Вспомогательные команды отделяются друг от друга при помощи косой черты (/). Перед первой вспомогательной командой косая черта может не ставится.
-
Текст, взятый в одинарные кавычки (используемый для идентификации меток), должен находиться в одной строке.
-
Строка с программным синтаксисом не должна превышать 80 знаков.
В качестве десятичного разделительного знака в спецификациях должна применяться точка (.), независимо от установок операционной системы Windows.
При интерпретации команд синтаксиса компьютер на различает верхний и нижний регистры (кроме меток, заключённых в одинарные кавычки). Команда может занимать любое количество строк; ввод пробела или переход на новую строку разрешается в той точке, где разрешено применение одиночного пробела, то есть перед и после косой черты, скобок, арифметических операторов или между именами переменных.
В программных файлах, которые должны работать в операционном модуле, каждая команда должна начинаться с новой строки. Каждая последующая строка одной и той же команды должна начинаться как минимум с одинарного пробела; поэтому в конце команды точка может не ставиться. Синтаксис отдельных команд Вы можете просмотреть при помощи справочной системы (см. разд. 4.9).
26.2 Выполнение готовой программы для SPSS
26.2 Выполнение готовой программы для SPSS
В рамках эксперимента в области психологии пятнадцать мужчин были подвергнуты тестированию на предмет концентрации внимания (далее ТКВ — тест концентрации внимания). При этом вся совокупность респондентов была разбита на две группы: восемь человек вошли в экспериментальную группу и семь в контрольную. Группы компоновались таким образом, чтобы в начале эксперимента усреднённые показатели обеих
групп были примерно равны. Затем респондентам из экспериментальной группы было предложено выпить по три кружки пива, а респондентам контрольной группы пришлось довольствоваться минеральной водой. Через час в обеих группах был повторно проведен ТКВ.
Конечно же, предметом этого теста является изучение влияния алкоголя на функциональные способности человека. Предположим, что данные этого эксперимента мы обрабатывали на большой ЭВМ. Тогда существовало бы, как правило, два файла, один из которых в столбцах форме содержал данные (файл alko.dat), а второй программу 8Р85(файл alko.sps). Файлы выглядят следующим образом:
Файл данных
1 | 1 | 15 | 19 |
2 | 2 | 20 | 16 |
3 | 2 | 14 | 13 |
4 | 1 | 17 | 21 |
5 | 1 | 22 | 24 |
6 | 2 | 18 | 14 |
7 | 2 | 22 | 19 |
8 | 1 | 19 | 18 |
9 | 2 | 17 | 16 |
10 | 1 | 14 | 18 |
11 | 2 | 17 | 17 |
12 | 1 | 15 | 17 |
13 | 1 | 18 | 18 |
14 | 2 | 17 | 14 |
15 | 1 | 20 | 21 |
Программный файл SPSS
DATA LIST FILE='\spssbuch\alko.dat'
/g 4 kltl 6-7 klt2 9-10.
COMPUTE kltdiff=klt2-klt1.
VARIABLE LABELS g "Группа" /
klt1 "Тест на концентрацию внимания Проба 1" /
klt2 "Тест на концентрацию внимания Проба 2" /
kltdiff "Тест на концентрацию внимания Повышение" .
VARIABLE LABELS
g 1 "Экспериментальная группа"
2 "Контрольная группа".
NPAR TESTS K-S(NORMAL)=klt1,klt2,kltdiff.
TEMPORARY. SELECT IF g=1.
T-TEST PAIRS=klt1 WITH klt2.
TEMPORARY. SELECT IF g=2.
T-TEST PAIRS=klt1 WITH klt2.
T-TEST GROUPS=g(1,2)
/VARIABLES=klt1,klt2,kltdiff.
После проверки значений ТКВ на предмет наличия нормального распределения, в данной программе будут исследоваться следующие вопросы:
-
Являются ли различными показатели ТКВ обеих групп в первой и во второй пробах?
-
Различаются ли показатели ТКВ и их изменения между обеими группами?
Для выполнения этой программы в SPSS for Windows у Вас существует две возможности:
-
Можно запустить SPSS for Windows, загрузить программу в редактор синтаксиса и после маркировки соответствующего текста, выполнить ее, нажав кнопку со значком Run Current (Выполнить текущее задание).
-
Можно запустить программу в операционном модуле SPSS.
26.2.1 Запуск из редактора синтаксиса
26.2.1 Запуск из редактора синтаксиса
Рассматриваемая программа для SPSS находиться в файле alko.sps, имеющемся на приложенном компакт-диске; данные для этой программы можно найти в этой же директории в файле alko.dat.
Не будем вдаваться в подробности того, как были созданы эти ASCII-файлы. Возможно, они были скопированы с какой-нибудь большой ЭВМ или созданы с помощью одного из многочисленных текстовых редакторов, например, редактора, поставляемого с MS-DOS.
-
После запуска SPSS for Windows выберите в меню File (Файл) Open (Открыть) Syntax... (Синтаксис) Откроется диалоговое окно Open File (Открыть файл).
-
Выберите директорию прилагаемого диска и выделите файл alko.sps (см. рис. 26.1).
-
Подтвердите выбор нажатием кнопки Open (Открыть). Инструкции программного файла появятся в окне редактора синтаксиса. При необходимости здесь же их можно и отредактировать.
-
Выберите в меню Edit (Правка) Select All (Выделить всё)
-
Щелчком на выключателе Run Current (Выполнить текущее задание) запустите программу на исполнение. Результаты расчёта будут выведены в окно просмотра.
-
После выбора меню File (Файл) Save as... (Сохранить как) появится диалоговое окно, в котором Вы можете указать имя файла (с рекомендуемым расширением: .spo) для сохранения содержимого окна просмотра.
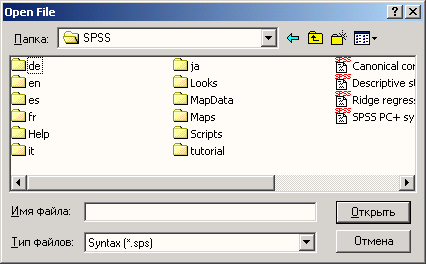
Рис. 26.1: диалоговое окно Open file (Открыть файл)
-
При выборе опции File (Файл) Print (Печать) Вы можете вывести содержимое окна просмотра на подключенный принтер.
-
При выходе из SPSS, после использования команды меню file (Файл) Close (Закрыть) на экране появится вопрос, не хотите ли вы сохранить рассчитанные данные в файле данных SPSS (рекомендуемое расширение: .sav).
1.gif

26.2.2 Операционный модуль
26.2.2 Операционный модуль
Ещё одну возможность запуска готовой SPSS-программы представляет операционный модуль. Выполнение программы происходит при этом не с помощью диалога с SPSS, a как бы на заднем плане (в фоновом режиме), причём во время расчёта Вы можете выполнять на компьютере и другие задачи.
Это очень удобно при выполнении ёмких процедур SPSS. Одной из таких процедур является, к примеру, кластерный анализ, в котором применяется иерархический метод (см. разд. 20.1) и необходимо обработать большое количество наблюдений.
Такое большое для кластерного анализа количество наблюдений (n=300) включает файл psych.sav, который наряду с номерами наблюдений содержит переменные а, Ь, и с, описывающие значения оценки состояния пациентов психиатрического отделения по соответствующим шкалам: на шкале А отображается уровень невротичности, на шкале В — адаптация к обществу и на шкале С — целенаправленность действий. Патологическими отклонениями считаются высокие значения по шкале А и В и низкие по шкале С. Попытаемся на основании этих трёх шкал разделить пациентов на группы.
-
Откройте файл psych.sav.
-
Выберите в меню Analyze (Анализ) Classify (Систематизировать) Hierarchical Cluster... (Иерархический кластер)
-
Перенесите переменные а, Ь, и с в поле тестируемых переменных.
-
Минуя выключатель Statistics (Статистики) установите область решений от 2 до 6 кластеров.
-
Через выключатель Method (Метод) активируйте стандартизацию значений (z-преобразование).
-
Деактивируйте вывод диаграмм.
Если Вы сейчас начнёте расчёт нажатием кнопки ОК, то программе для расчёта понадобится несколько минут. Мы произведём расчёт в операционном модуле, для чего нам сначала необходимо создать файл с соответствующим программным синтаксисом.
-
Для этого в диалоговом окне Hierarchical Cluster Analysis (Иерархический кластерный анализ) щёлкните на переключателе Paste (Вставить), после чего в редактор синтаксиса будут внесены следующие команды SPSS:
PROXIMITIES а Ьb с
/MATRIX OUT ("C:\TEMP\spssclus.tmp") /VIEW= CASE
/MEASURE= SEUCLID
/PRINT NONE
/STANDARDIZE= VARIABLE Z
. CLUSTER
/MATRIX IN ("C:\TEMP\spssclus.tmp") ' /METHOD BAVERAGE
/PRINT SCHEDULE CLUSTER(2,6)
/PLOTS NONE.
ERASE FILE= "C:\TEMP\spssclus.tmp".
-
Выбрав в меню File (Файл) Save as... (Сохранить как) Сохраните содержимое редактора синтаксиса, к примеру, в файле claSter.sps.
-
Завершите работу в редакторе синтаксиса выбором команды меню File (Файл) Close (Закрыть)
-
Из стартового меню рабочего стола запустите операционный модуль SPSS (SPSS 10.0 Production Facility) (см. рис. 26.2).
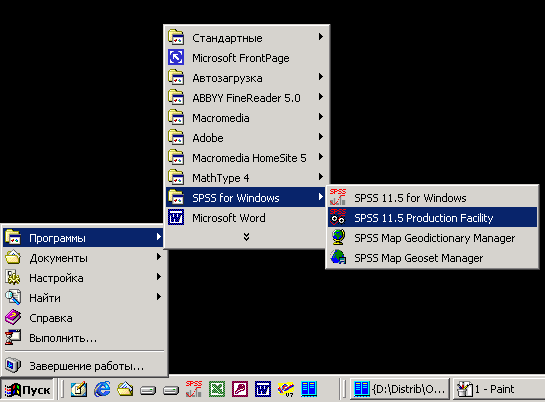
Рис. 26.2: Меню Start (Пуск) рабочего стола операционной системы Windows 2000
Откроется диалоговое окно операционного модуля SPSS (см. рис. 26.3).
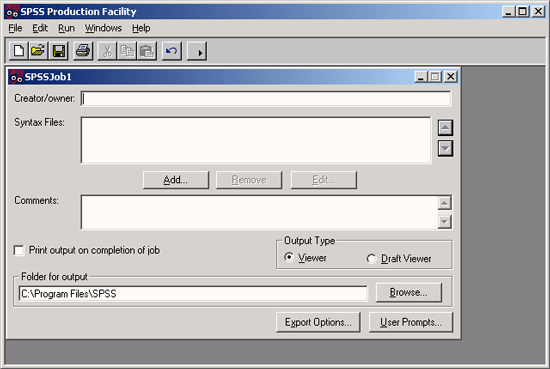
Рис. 26.3: Диалоговое окно SPSS Production Facility (Операционный модуль SPSS)
-
Щёлкните на переключателе Add... (Добавить). Откроется диалоговое окно Attach SPSS Syntax File (Вложить файл синтаксиса SPSS).
-
Выделите, сохранённый Вами, файл cluster.sps.
-
Нажатием выключателя Open (Открыть) вернитесь в исходное диалоговое окно. Синтаксические файлы, открытые по ошибке, Вы можете удалить из диалогового окна при помощи выключателя Remove (Удалить). В поле Folder for output (Папка результатов) Вы можете указать место, куда должен быть помещён файл с результатами, рассчитанными операционным модулем.
-
Укажите, например, в качестве папки для результатов C:\SPSSBOOK.
-
Нажмите выключатель Edit (Править).
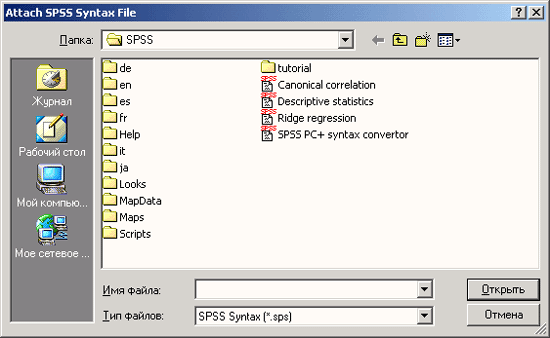
Рис. 26.4: Диалоговое окно Attach SPSS Syntax File (Вложить файл синтаксиса SPSS)
Откроется тестовый редактор, в котором Вы можете дополнительно отредактировать открытую SPSS-программу. В нашем примере при помощи команды GET следует указать ссылку на истинное расположение соответствующего файла данных. После ввода этой команды программа SPSS будет выглядеть следующим образом:
GET FILE='С:\SPSSBUCH\psych.sav'.
PROXIMITIES а b с
/MATRIX OUT ("С:\WIN95\TEMP\spssclus.tmp") /VIEW= CASE /MEASURE= SEOCLID
/PRINT NONE /STANDARDIZE:?
VARIABLE Z .
CLUSTER
/MATRIX IN ("C:\WIN95\TEMP\spssclus.tmp") /METHOD BAVERAGE
/PRINT SCHEDULE CLUSTER(2,6)
/PLOTS NONE.
ERASE FILE= "C:\WIN95\TEMP\spssclus.tmp".
-
Посредством выбора меню сохраните программу, изменённую в текстовом редакторе File (Файл) Save (Сохранить) и закройте окно редактора.
-
Теперь сохраните программу в форме операционной задачи. Для этого выберите в меню File (Файл) Save as... (Сохранить как)
Откроется диалоговое окно Save as Production Job (Сохранить как операционную задачу). Для файла операционной задачи предлагается расширение .spp (см. рис. 26.5).
-
Наберите имя файла C:\SPSSBOOK\clasjob.spp и покиньте диалоговое окно нажатием кнопки Save (Сохранить).
-
Вновь вернувшись в диалоговое окно SPSS Production Facility (Операционный модуль SPSS) выберите в меню Run (Выполнить) Production Job (Операционная задача)
Пока выполняется операционная задача, вы можете заняться другой работой. После окончания решения задачи Вы увидите, что результаты сохранены в формате файла окноа просмотра с расширением .spo под именем, соответствующим имени файла рассчитанной задачи.
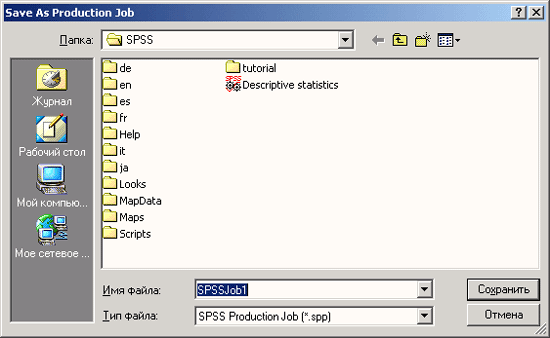
Рис. 26.5: Диалоговое окно Save as Production Job (Сохранить как операционную задачу)
2.gif

3.gif

4.gif

5.gif

26.3 Объединение синтаксиса и диалогового режима
26.3 Объединение синтаксиса и диалогового режима
На нескольких примерах мы покажем то, как программный синтаксис можно с пользой внедрить в диалоговый режим SPSS. Во всех статистических процедурах, установки, произведенные в соответствующих диалоговых окнах, могут быть перенесены в редактор синтаксиса при помощи специального переключателя. При необходимости, Вы можете дополнительно отредактировать этот синтаксис для того, чтобы добиться выполнения некоторых задач, недоступных в режиме работы через диалоговые окна. Конечно же, для этого необходимо знать особенности подобных синтаксических возможностей.
В качестве первого примера рассмотрим тест Стьюдента для зависимых выборок. Тест Стьюдента для зависимых выборок был использован в разделе 13.2 при сравнения двух
переменных chol0 и chol1 из файла hyper.sav. Синтаксис, генерируемый программой после нажатия переключателя Paste (Вставить), выглядит следующим образом:
T-TEST
PAIRS= chol0 WITH
chol1 (PAIRED)
/CRITERIA=CIN(.95)
/MISSING=ANALYSIS.
Если Вы хотите сравнить между собой не только переменные chol0 и chol 1, а и попарно сравнить все четыре переменные chol0, chol1, cho!6 и chol 12, то в итоге при помощи данного диалогового окна Вам придётся произвести шесть операций парного сравнения. Это довольно утомительный процесс и, если было бы необходимо попарно сравнить еще большее количество переменных, то он отнял бы у Вас довольно много времени.
-
Программный синтаксис, отображаемый в редакторе синтаксиса, приведите к следующему виду
T-TEST
PAIRS= chol0, chol1, chol6, chol12
/CRITERIA=CIN(.95) /MISSING=ANALYSIS .
-
Начните расчёт
Попарно будут протестированы все переменные, перечисленные во вспомогательной команде PAIRS.
Похожий пример возьмём из раздела 15.2, где для этих четырёх переменных производится расчёт корреляционной матрицы Пирсона. Вы увидите следующий исходный синтаксис
CORRELATIONS
/VARIABLES=chol0 choll chol6 chol12
/PRINT=TWOTAIL SIG
/MISSING=PAIRWISE .
Если же Вы, допустим, желали бы рассчитать не совокупную корреляционную матрицу, а, например, проверить корреляции одной только переменной chol0 с переменными chol1, chol6 и chol 12, то Вам пришлось бы произвести три довольно объёмных расчёта. И в этом случае Вы можете очень эффективным способом отредактировать программный синтаксис, применив ключевое слово WITH:
CORRELATIONS
/VARIABLES=chol0 WITH chol1 chol6 chol12
/PRINT=TWOTAIL SIG
/MISSING=PAIRWISE .
Следующий пример касается трансформации данных, а именно, образования новых переменных при помощи некоторой формулы. С этой целью вновь вернёмся к файлу hyper.sav, точнее говоря — к переменным rrs0, rrs1, rrs6, rrs12, rrd0, rrd1, rrd6 и rrd12, отражающим состояние систолического и диастолического давлений в четыре различных момента времени. Образуем шесть новых переменных, которые будут отображать показатели трёх последующих моментов времени, выраженные в процентах от исходной величины (переменные rrs0 и rrd0). Для этого после выбора меню Transform (Трансформировать) Count (Подсчитать) необходимо задать в общей сложности шесть формул вида
prrs1=(rrs1/rrs0)*100
где prrs1 — в нашем примере, процентный показатель, соответствующий переменной rrs1, соотнесённой к исходной величине rrs0. Но если Вы будете в этом случае применять синтаксис, то, пожалуй, все можно сделать гораздо быстрее.
-
Выберите в меню File (Файл) New (Новый) Syntax... (Синтаксический)
-
В редакторе синтаксиса введите шесть следующих команд:
COMPOTE prrsl=rrs1/rrs0*100.
COMPOTE prrs6=rrs6/rrs0*100.
COMPOTE prrsl2=rrs12/rrs0*100
. COMPOTE prrdl=rrdl/rrd0*100.
COMPOTE prrd6=rrd6/rrd0*100.
COMPOTE prrdl2=rrd12/rrd0*100.
EXECOTE.
-
Затем щёлкните на Edit (Правка) Select All (Выделить всё)
-
Нажатием кнопки Run Current (Выполнить текущее задание) начните выполнение вышеуказанной последовательности команд.
Для использования в дальнейших расчётах у Вас появятся шесть новых переменных, которые будут отображать искомые процентные показатели. Если Вы посмотрите на шесть приведенных команд COMPUTE, то наверняка заметите, что все они построены по одному и тому же принципу. Меняются только числители и знаменатели, на месте которых необходимо подставлять соответствующие переменные. Абсолютно такую же последовательность команд COMPUTE можно создать при помощи команд DO REPEAT — END REPEAT. Введите в редакторе синтаксиса следующую структуру команд:
DO REPEAT p=prrs1,prrs6,prrs12,prrd1,prrd6,prrd12/
z=rrs1,rrs6,rrs12,rrd1,rrd6,rrd12/
a=rrs0,rrs0,rrs0,rrd0,rrd0,rrd0.
COMPOTE p=z/a*100.
END REPEAT .
Здесь р, z и а являются, так называемыми, переменными-заменителями для реальных переменных, используемых при вычислениях. Они обрабатываются слева направо согласно заданной команды COMPUTE. В рассмотренном примере затраты времени на ввод данных вряд ли стали меньше, но при наличии большего количества переменных в списках экономия времени будет уже ощутимой.
26.4 Программы операций над матрицами
26.4 Программы операций над матрицами
Между двумя командами SPSS: MATRIX и END MATRIX можно поместить программу, позволяющую выполнять операции над матрицами. Для изучения этой возможности рассмотрим два примера.
Пётр пошёл за покупками в магазин и принёс домой 2 литра молока, 10 яиц, 3 плитки шоколада и 5 стаканчиков йогурта, за что он заплатил в сумме 11,80 грн. На следующий день Юля купила 1 литер молока, 15 яиц, 2 плитки шоколада и 4 стаканчика йогурта за 10,01 грн. После этого Николай заплатил 15,07 грн за 3 литра молока, 12 яиц, 5 плиток шоколада и 3 стаканчика йогурта, и, в конце концов, Лене 2 литра молока, 20 яиц, 5 плиток шоколада и 5 стаканчиков йогурта обошлись в 15,74 грн. И никто из них не принёс при этом расчётный чек из магазина. Мама хочет узнать, сколько же стоит каждый продукт в отдельности. Пётр, который учится в пятом классе, предложил решение при помощи системы линейных уравнений:
2А | + | 10В | + | зс | + | 5D | 1180 |
А | + | 15В | + | 2С | + | 4D | 1001 |
ЗА | + | 12В | + | 5С | + | 3D | 1507 |
2А | + | 20В | + | 4С | + | 5D | 1574 |
Юля, ученица восьмого класса, привила эти уравнения к матричному виду:
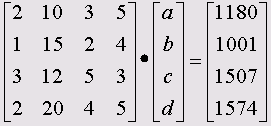
Николай записал эту матрицу в символьной форме:
АХ=С
и соответственно
X = А-1 С
Юля решает эту задачу в SPSS, для чего и пишет следующую программу:
MATRIX.
COMPUTE a={2 ,10 ,3,5;1,15,2,4;3,12,5,3;2,20,4,5}. COMPUTE с={1180,-1001,-1507;1574} . COMPUTE x=INV(a)*c.
PRINT x.
END MATRIX.
-
Чтобы выполнить эту программу выберите в меню File (Файл) Open (Открыть) Syntax... (Синтаксический)
-
Выберите тип файлов Syntax (*.sps) (Синтаксис). На прилагаемом учебном диске найдите файл sabine.sps. В окне редактора синтаксиса появится необходимая нам программа.
-
Выберите теперь Edit (Правка) Select All (Выделить всё)
-
Начните выполнение программы нажатием кнопки Run Current (Выполнить текущее задание).
В окне просмотра появятся результаты расчёта: х
119,0000000
26,0000000
134,0000000
56,0000000
Теперь видно, что один литр молока стоит 1,19 грн, одно яйцо 0,26 грн, одна плитка шоколада 1,34 грн и один стаканчик йогурта 0,56 грн. Для написания программ, использующих операции с матрицами, существует множество различных инструкций и функций. Для выяснения их смысла, обращайтесь, пожалуйста, к первоисточнику по SPSS.
В следующем примере мы хотим запрограммировать начальный этап факторного анализа, а именно, рассчитать собственные значения корреляционной матрицы.
-
Для этого примера используйте данные из файла ausland.sav, рассмотренного в гл. 19, и наберите в редакторе синтаксиса следующую SPSS-программу:
CORRELATIONS VARIABLES=A1
TO A15/MATRIX=OUT (*) .
MATRIX.
MGET FILE=*/TYPE=CORR.
CALL eigen(cr,evec,ewerte) .
PRINT ewerte.
END MATRIX.
-
Выберите в меню Edit (Правка) Select All (Выделить всё)
-
Начните выполнение программы нажатием кнопки со значком Run Current (Выполнить текущее задание).
После этого в окне просмотра будут показаны собственные значения; первые пять из них выглядят следующим образом:
EWERTE
5,146239283
1,945444977
1,414941459
,990117365
,935705222
Вычисленные собственные значения полностью соответствуют результатам, полученным в гл. 19.
6.gif
26.5 Сценарии
26.5 Сценарии
В SPSS интегрирован язык сценариев (Visual Basic), предоставляющий некоторые возможности для автоматизации вычислительных процессов. Степень использования сценариев зависит от уровня Ваших познаний и может быть разбита на три уровня:
1. Использование стандартных сценариев, имеющихся в SPSS: это может сделать каждый пользователь, так как в этом случае не требуется ни каких навыков программирования.
2. Модифицирование имеющихся сценариев: для этого необходимо располагать некоторыми базовыми знаниями.
3. Написание собственных сценариев: для этого необходимы навыки программирования на Visual Basic.
В этой книге мы ограничимся только те, что при помощи примера покажем применение сценариев, поставляемых вместе с SPSS. Изложение материала по написанию собственных сценариев и в особенности изучение языка Visual Basic, очень сильно увеличило бы объём данной вводной книги.
Кроме того, использование сценариев при работе с SPSS только начинает набирать обороты и сценарии поставляемые вместе с SPSS кажутся ещё не слишком продвинутыми. Однако, следить за сообщениями фирмы SPSS всё же полезно; время от времени в журнале для пользователей "SPSS direct" представляются новые сценарии, которые можно интегрировать в программу.
26.5.1 Применение сценария
26.5.1 Применение сценария
Для изучения принципа работы со сценариями должно быть достаточно рассмотрения только одного сценария, который в сводных таблицах меняет идентификатор Sig на р.
-
Откройте файл hyper, sav.
-
Выберите в меню Analyze (Анализ) Compare Means (Сравнить средние значения) Paired-Samples T Test... (Т-тест для спаренных выборок)
-
Переменным chol0 и chol1 присвойте статус спаренных переменных. Основные результаты теста отображены в следующей таблице:
Paired Samples Test
(Тест спаренных выборок) | |||||||||
| Paired Differences | t | Df | Sig. (2-sided) Значи-мость (двухсто ронняя)) | |||||
Mean (Сред- значе-ние) | Std. Deviation (Станда- ртное откло- нение) | Std. Error Mean (Стандар-тная ошибка среднего значения) | 95% Confidence Interval of the Difference (95 %-й доверительный интервал разности) | ||||||
Lower (Ниж-ний предел) | Upper (Верх-ний предел) | ||||||||
Pair1 (Пар а1) | Chole-sterin, Ausga- ngswert -Cholesterin, nach 1 Monat (Холе- стирин, исходный показатель -холе- стерин, спустя 1 месяц) | -1,93 | 26,09 | 1,98 | -5,83 | 1,98 | -,974 | 173 | ,332 |
-
В окне просмотра один раз щёлкните на сводной таблице.
-
Выберите в меню. Utilities (Утилиты) Run Script... (Выполнить сценарий) Откроется диалоговое окно Run Script (Выполнение сценария).
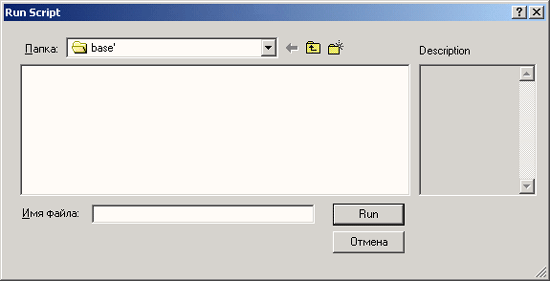
Рис. 26.6: Диалоговое окно Run Script (Выполнение сценария)
-
В директории PROGRAM F1LES\SPSS\SCRIPTS просмотрите список сценариев, предлагаемых в SPSS.
-
Выделите сценарий с именем Change sig to p.
-
И нажатием кнопки Run (Выполнить), пошлите его на исполнение. В окне просмотра появится изменённая сводная таблица.
Paired Samples Test
(Тест спаренных выборок) | |||||||||
| Paired Differences |
|
|
| |||||
|
| Std. Error | 95% Confidence Interval of the | ||||||
| Mean (Среднее значение) | Std. Deviation (Станда- ртное откло- нение) | Mean (Стандар-тная ошибка среднего значения) | Difference (95 %-й доверительный интервал разности) | t | Df | Р = | ||
Lower (Ниж- ний предел) | Upper (Верх- ний предел) | ||||||||
Pair 1 | Cholesterin, |
|
|
|
|
|
|
|
|
(Пар а1) | Ausga- ngswert -Choles- terin, nach 1 Monat |
|
|
|
|
|
|
|
|
| (Холе- стирин, | -1,93 | 26,09 | 1,98 | -5,83 | 1,98 | -,974 | 173 | ,332 |
| исходный |
|
|
|
|
|
|
|
|
| показатель - |
|
|
|
|
|
|
|
|
| холе- стерин, спустя 1 месяц) |
|
|
|
|
|
|
|
|
Действие остальных сценариев рассмотрите, пожалуйста, самостоятельно.
7.gif

26.5.2 Автоматические сценарии
26.5.2 Автоматические сценарии
Специальной формой сценариев являются, так называемые, автоматические сценарии. Если они активированы, то автоматически воздействуют на компоновку выводимых результатов некоторых процедур. Для изучения работы автоматических сценариев рассмотрим пример, в котором мы будем управлять компоновкой корреляционной матрицы.
-
Откройте файл hyper.sav.
-
Выберите в меню Edit (Правка) Options... (Параметры)
-
В диалоговом окне Options (Параметры) перейдите на регистрационную карту Scripts (Сценарии). Вам будет показан список автоматических сценариев, хранящихся в директории PROGRAM FILES\SPSS\SCRIPTS.
Рис. 26.7: Доступные автоматические сценарии
-
Выберите подходящий вид расчёта и просмотрите результаты действия этого авто-сценария.
8.gif

26.5.3 Редактор сценариев
26.5.3 Редактор сценариев
Если у вас появилось желание модифицировать имеющиеся сценарии или написать новые, воспользуйтесь редактором сценариев. Мы ограничимся только открытием и просмотром одного существующего сценария в редакторе сценариев.
-
Выберите в меню File (Файл) Open (Открыть) Script... (Сценарий)
Выберите тип файлов *.sbs (SPSS-сценарий) и выберите в директории PROGRAM FILES\SPSS\SCRIPTS сценарий, очищающий окно просмотра результатов или навигатор (то есть устраняющий примечания) (Clean navigator.sbs).
-
Выделите этот сценарий и подтвердите выбор нажатием Open (Открыть). Редактор сценариев будет выглядеть так, как изображено на рисунке 26.8.
Рис. 26.8: Редактор сценариев Просмотрите этот сценарий, чтобы иметь представление о языке сценариев.
9.gif
